


Reducción de riesgos
Denodo Platform proporciona datos en tiempo real que ayudan a gestionar los riesgos empresariales y a reducir las sanciones por incumplimiento. Además, el rápido desarrollo de Denodo Platform y las capacidades de iteración rápida ayudan a reducir los riesgos de los proyectos de TI.


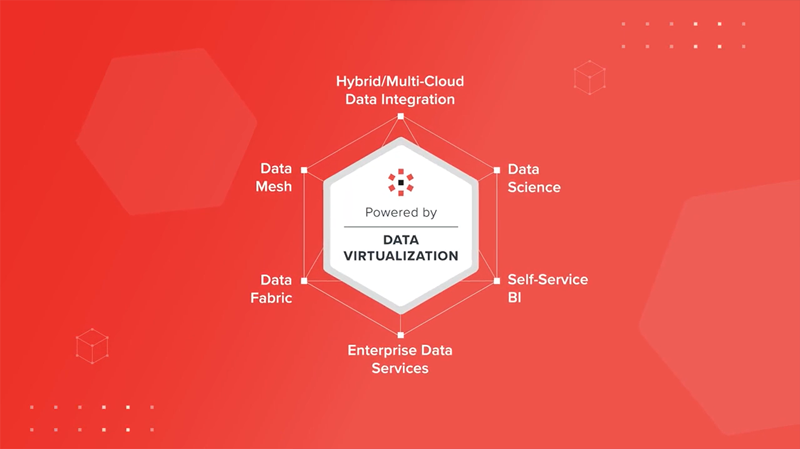
A medida que crece la demanda de datos, las organizaciones necesitan reducir el tiempo de obtención de valor acelerando los esfuerzos de ingeniería de datos. La mayoría de los enfoques actuales son demasiado lentos y costosos, provocan la reinvención y pueden dar lugar a datos incoherentes. La virtualización de datos, por el contrario, proporciona un enfoque ágil para crear productos de datos. Con la virtualización de datos, los productos de datos pueden gobernarse en un solo lugar y suministrarse a los consumidores sin replicación. La virtualización de datos es una base excelente para la arquitectura de datos distribuidos y los casos de uso modernos.
Arquitectos de datos
La virtualización de datos añade flexibilidad a la integración de datos para que los arquitectos de datos puedan hacer evolucionar con éxito sus estrategias y arquitecturas de datos, a fin de aprovechar al máximo las últimas tecnologías e innovaciones de datos.
Ingenieros de datos
Fácil de aprender y enormemente productiva, la virtualización de datos permite a los ingenieros de datos ofrecer más vistas de datos, más rápido, para que puedan obtener un mayor valor empresarial cuanto antes.
Científicos y analistas de datos
La virtualización de datos proporciona a los científicos y analistas de datos acceso instantáneo a todos los datos que deseen, de la forma que deseen.
Líderes analíticos
Data virtualization simplifies and accelerates access to the data needed to fuel analytics and applications.
CIOs y CTOs
El enfoque de integración ágil de la virtualización de datos permite a los CIOs y CTOs responder más rápidamente a unas necesidades empresariales en constante cambio y hacerlo con una menor inversión.
Administradores de datos
La virtualización de datos ayuda a los administradores de datos a implementar y aplicar modelos y estándares de datos empresariales para proporcionar datos coherentes, seguros y gobernados.


Engie
"Siempre nos había resultado complicado completar a tiempo los proyectos de integración de datos en Engie México. A menudo tardábamos entre tres y seis meses, y en algunos casos incluso un año, en entregar un proyecto de integración de datos. Denodo cambió esta situación para nosotros; ahora podemos entregar un proyecto de integración completo en dos semanas."

Seacoast Bank
"La tecnología de virtualización de datos de Denodo ha desempeñado un papel importante a la hora de permitir a nuestros usuarios empresariales obtener información valiosa a través de informes de autoservicio. Denodo Platform ha aumentado significativamente la velocidad a la que se llevan a cabo los negocios en Seacoast Bank."

Coca-Cola Peninsula Beverages
"Denodo Platform nos ha permitido comprender mejor cómo se utilizan los datos en nuestra organización, lo que nos ha ayudado a identificar conjuntos de datos similares que se utilizan en varios departamentos. El uso de la plataforma ha eliminado la necesidad de conciliar los datos entre los diferentes departamentos y también ha acelerado el tiempo de respuesta para hacer que estos datos estén disponibles, mediante la introducción de la automatización."